德克萨斯大学奥斯汀分校脑机接口实验室发布了一篇论文《SPEECH SYNTHESIS USING EEG》被ICASSP 2020所收录。不同于常见的sequence-to-sequence 语音合成模型, 该论文采用了近期所提出的EEG脑电图特征集来进行建模。其中,一个RNN自回归模型被用来从EEG特征中直接预测声学特征。这种具有可行性的方案可用于帮助肌萎缩性侧索硬化症(ALS)失去语言恢复能力的患者。
一、背景介绍
脑电图是一种非侵入性的测量人脑电活动的方法。EEG具有像侵入性ECoG信号一样的高时间分辨率。由于EEG完全是一种非侵入性技术,因此受试者无需像记录EEG的ECoG那样进行脑部手术,只需 脑电图传感器放置在对象的头皮上以获取记录。本篇论文尝试使用GRU来进行语音合成探索。
二、方法介绍
令人兴奋的是,执行此脑电图语音生成的模型仅仅是一个简单的RNN模型。详细来说,本篇论文的模型由两层GRU层组成,(第一层256个单元,第二层128个单元),最后一层GRU连接到一个时间分布的密集层(13个单元),用于在每个时间步长预测13-维特征。在每一层GRU后面添加了一个dropout 正则化层,其中dropout比率为0.2。整个模型的输入向量为EEG脑电图特征,输出为声学特征。目标函数为MSE,实验数据的80%用作于训练集,10%作为验证集用于参数调优,而剩下的10%用作于测试集。
三、实验介绍
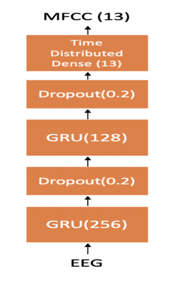 图1 EEG-MFCC模型
图1 EEG-MFCC模型
4名实验对象参与了录制实验,这四名均为德克萨斯大学奥斯汀分校的本科学生,大约20来岁,其中有3名女性,和1名男性。这四名实验对象,首先听一段录制好的语音,然后再将听到的内容,大声朗读出来。EEG脑电波在他们听录音以及朗诵的时候,分别被记录了下来,分别被标记为听力EEG和口语EEG。这四句话分别为"Hi Bixby", "Call Mom", "Open Camera" and " What's the weather". 实验中收集了70个语音-EEG对。实验中采用的是脑视脑电图记录硬件。
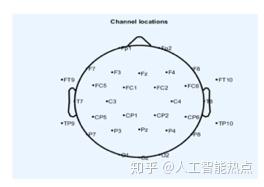 图2 实验中使用的盖帽的EEG通道位置
图2 实验中使用的盖帽的EEG通道位置
我们的EEG帽具有32个湿EEG电极,其中一个电极接地,如图2所示。我们使用EEGLab 来获取EEG传感器位置映射。它基于32个电极的标准10-20 EEG传感器放置方法进行试验。我们计算了三种类型的性能指标,即mel倒谱系数(MCD),均方根误差(RMSE)和测试期间预测的MFCC与测试集的真实MFCC之间的归一化RMSE,以评估测试集的性能。
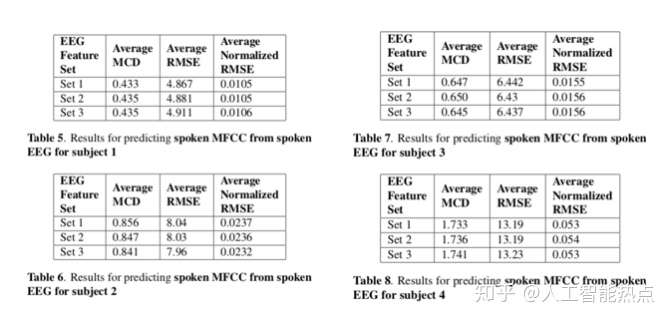 图3 实验中使用的盖帽的EEG通道位置
图3 实验中使用的盖帽的EEG通道位置
表1-4展示了对于三组EEG 特征集,set1-3, 四个实验对象的听力 EEG 至听力语音合成的效果,表5-8展示了对于这三组EEG特征集,set1-3,这四个实验对象的口语EEG至朗读语句的合成效果。
实验结果表明,在有充足的数据的情况下,EEG的特征提取,对于语音的合成效果影响微乎其微。然而,不同说话人所产生的完全不同的ACD,说明了不同的人在听到或朗读同一句话的时候,所产生的脑电波是完全不同的。
四、总结
本文探索了一个简单的GRU模型将人类的脑电波转化成相应的语音的过程,是脑电波语音生成的先行者,这为肌萎缩性侧索硬化症(ALS)等失去语言恢复能力的患者,提供了再次说出话语的能力,同时也为脑机控制人机交互提供了可能性。